
Day 18/30 - DEEP DIVE SOLUTIONS: SQL, PYTHON, ETL, DATA MODELING
Solutions for March 19th, 2025 CHALLENGE – Unlock the Full Breakdown + Live Runnable Code!

👋 Hello Data Engineers!
Today, we’re diving deep into SQL Window Functions, Python String Optimization, Fault-Tolerant ETL Pipelines, and OLTP Schema Design. If you've upgraded to Deep Dive, you're already ahead of 1000+ data engineers mastering these concepts with expert breakdowns and runnable code.
If you haven’t upgraded yet, you're missing out on real-world optimizations, performance tuning techniques, and job-ready problem-solving skills.
💡 Upgrade now and stay ahead of the competition!
📌 SQL Deep Dive: Window Functions - LEAD() and LAG()
Challenge Recap:
❓ Which SQL function helps access the value from the next row within the same partition?
🔘 A) ROW_NUMBER()
🔘 B) RANK()
🔘 C) LAG()
🔘 D) LEAD()
✅ Answer: Option D - LEAD()
Why This Happens:
LEAD() allows referencing values forward within the same partition, making it useful for time-series analysis, session tracking, and sequential comparisons.
Where It's Used in Real-World Applications:
Financial Analysis: Comparing stock prices between consecutive days.
User Behavior Tracking: Analyzing customer session activity (e.g., time between logins).
Sales Forecasting: Checking revenue trends across different time periods.
Run & Test on OneCompiler:
1️⃣ Open OneCompiler and select PostgreSQL.
2️⃣ Create a sample table:
CREATE TABLE sales (
id SERIAL PRIMARY KEY,
customer_id INT,
purchase_date DATE,
amount DECIMAL(10,2)
);
INSERT INTO sales (customer_id, purchase_date, amount) VALUES
(1, '2025-03-15', 100.00),
(1, '2025-03-16', 200.00),
(1, '2025-03-17', 150.00),
(2, '2025-03-16', 300.00),
(2, '2025-03-18', 400.00);3️⃣ Test LEAD() in action:
SELECT customer_id, purchase_date, amount,
LEAD(amount) OVER (PARTITION BY customer_id ORDER BY purchase_date) AS next_amount
FROM sales;4️⃣ Click Run and analyze the output.
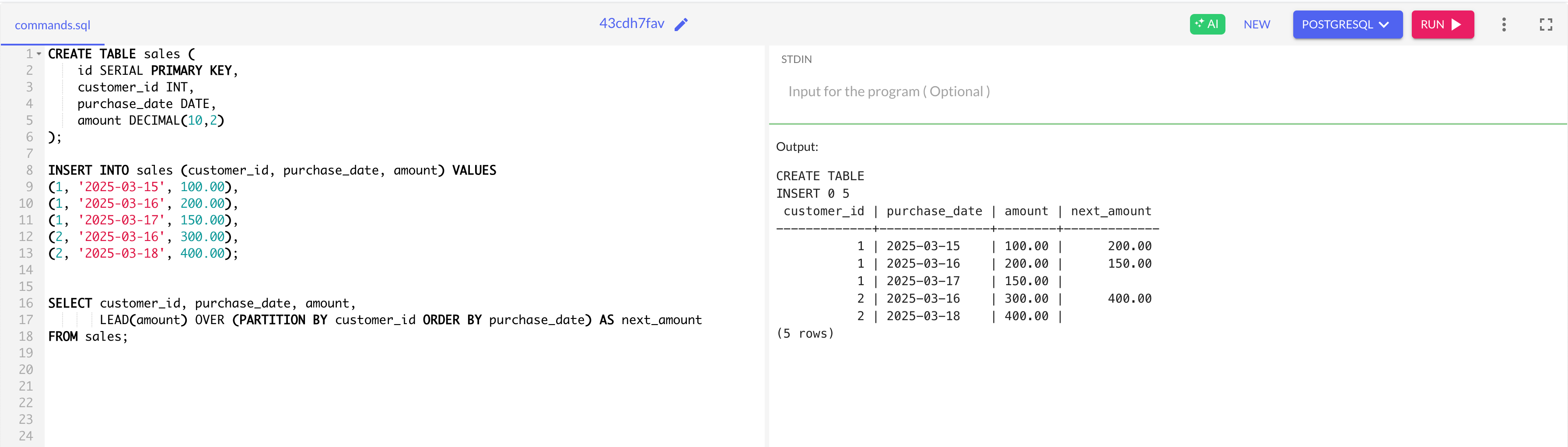
What’s Happening in the Output?
The
LEAD()function retrieves the next row's amount per customer, helping us compare purchases over time.Missing values (NULLs) appear if there’s no next row, which we can handle with default values.
Best Practices:
✔️ Use LAG() for backward-looking comparisons.
✔️ Combine PARTITION BY with LEAD() for grouped analysis.
✔️ Handle NULLs with COALESCE() to replace missing values.
🐍 Python Deep Dive: Efficient String Concatenation
Challenge Recap:
❓ Which method is the most memory-efficient way to concatenate a large number of strings in Python?
🔘 A) + operator inside a loop
🔘 B) ''.join(list_of_strings)
🔘 C) f-strings in a loop
🔘 D) concatenate() from NumPy
✅ Answer: Option B - ''.join(list_of_strings)
Why This Happens:
Using + in loops creates multiple intermediate copies, leading to high memory consumption. The join() method is optimized for reducing redundant memory allocations.
Where It's Used in Real-World Applications:
Log Processing: Merging large log files efficiently.
Text Analytics: Cleaning and concatenating large text datasets.
ETL Pipelines: Efficiently formatting JSON and CSV exports.
Run & Test on OneCompiler:
1️⃣ Open OneCompiler and select Python 3.
2️⃣ Test memory usage with different methods:
import sys
# Reduce the list size to avoid timeout issues in OneCompiler
list_of_strings = ["data"] * 10**5 # Reduce from 10**6 to 10**5
# Using join() (optimized)
concatenated_join = ''.join(list_of_strings)
print("Memory (join method - optimized):", sys.getsizeof(concatenated_join)) # More efficient4️⃣ Click Run and analyze the output.

Best Practices:
✔️ Use ''.join() for concatenation.
✔️ Avoid + inside loops, as it increases memory overhead.
✔️ For massive datasets, use StringIO instead of in-memory strings.