

📢 Day 6/30 - SQL, PYTHON, ETL, DATA MODELING CHALLENGE Solutions🔥
Solutions for March 3rd, 2025 CHALLENGE – unlock solutions + Reasoning! 🚀

👋 Hey Data Engineers!
Welcome to Day 6 of the 30-Day Data Engineering Challenge 🚀. Today, we’re diving into SQL Window Functions, Python Dictionary Mutability, ETL Deduplication, and Data Modeling.💡 What stood out to you today? Drop your thoughts in the comments!👇
✅ FREE Solutions + Reasoning → Now Available
📌 SQL Challenge - Subqueries Deep Dive
🔹 Concept: Using subqueries to filter and transform data dynamically.
👉 Question: Which of the following queries correctly uses a subquery?
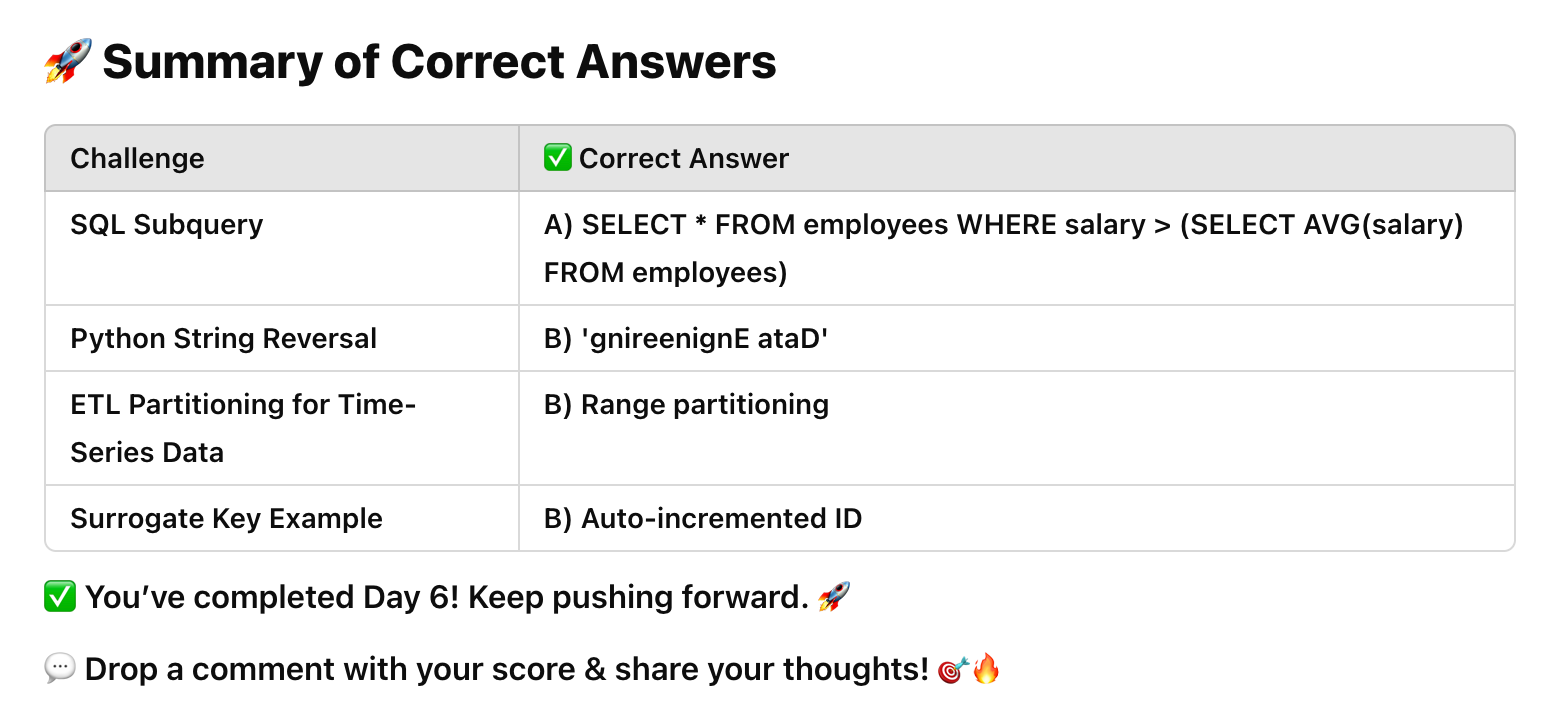
✅ Answer: A) SELECT * FROM employees WHERE salary > (SELECT AVG(salary) FROM employees)
📖 Explanation
A subquery is a query within a query that helps filter, compute, or transform data dynamically.
Option A correctly uses a subquery inside the
WHEREclause to compare each employee’s salary to the average salary.Option B uses
GROUP BY, which is aggregation but not a subquery.Option C filters data but does not contain a subquery.
Option D is a simple
SELECT *query without filtering or transformation.
💡 Best Practices for Using Subqueries:
✔ Use subqueries when filtering based on aggregated values (AVG, MAX, MIN).
✔ Optimize by using JOINs instead of subqueries where possible for better performance.
✔ Use correlated subqueries only when necessary, as they execute multiple times.
🐍 Python Challenge - String Manipulation Deep Dive
🔹 Concept: Reversing strings using Python slicing techniques.
👉 Question: What will be the output of this Python code?
text = 'Data Engineering'
print(text[::-1])✅ Answer: B) 'gnireenignE ataD'
📖 Explanation
In Python, [::-1] is a slicing technique that reverses a string.
The first
:means "use the full string."The second
:means "use the default step."-1means "step backward," reversing the string.
🔹 Expected Output:
'gnireenignE ataD'💡 Best Practices for String Manipulation in Python:
✔ Use slicing ([::-1]) for reversing strings efficiently.
✔ Use .join(reversed(string)) if working with iterators.
✔ For performance-heavy tasks, consider using NumPy for vectorized operations.
⚡ ETL Challenge - Data Partitioning Deep Dive
🔹 Concept: Efficiently partitioning large datasets for better query performance.
👉 Question: Which partitioning strategy is most effective for time-series data in ETL?
✅ Answer: B) Range partitioning
📖 Explanation
Range partitioning divides data into continuous ranges, making it ideal for time-series data (e.g., partitioning by date/month).
Hash partitioning distributes data randomly, which is better for load balancing but not ideal for time-based queries.
List partitioning is used for categorizing data by specific values (e.g., country names).
None of the above is incorrect because range partitioning is the best approach for time-series data.
💡 Best Practices for Partitioning Data in ETL:
✔ Use range partitioning for time-series datasets to optimize queries.
✔ Avoid too many partitions, as it can degrade performance.
✔ Use partition pruning techniques in SQL to speed up queries on partitioned tables.
📊 Data Modeling Challenge - Surrogate vs. Natural Keys Deep Dive
🔹 Concept: Choosing the right primary key strategy for database design.
👉 Question: Which of the following is an example of a surrogate key?
✅ Answer: B) Auto-incremented ID
📖 Explanation
A surrogate key is a system-generated unique identifier that has no real-world meaning.
Option B (Auto-incremented ID) is a classic surrogate key because it’s generated by the database and not derived from real-world attributes.
Option A (SSN), C (Email Address), and D (Passport Number) are all natural keys because they come from real-world attributes.
💡 Best Practices for Choosing Primary Keys:
✔ Use surrogate keys for large databases to avoid dependency on changing real-world values.
✔ Natural keys should be used when they are truly unique and unchangeable.
✔ Avoid using composite keys unless necessary for multi-table relationships.
🔥 Don’t Just Read—Upgrade & Experience It!
Every deep dive walks you through the concepts step by step—but more importantly, you get runnable code to test on onecompiler.com, so you truly grasp the concepts instead of just reading theory.
🚀 This isn’t just another tutorial—it’s your personal blueprint to mastering Data Engineering.
🔥 Want the Full DEEP DIVE Analysis?
Upgrade to PAID Monthly or Annual Membership