
File Handling Like a Pro
How Data Engineers read, write, and organize files at scale.

Welcome to Zero2DataEngineer — Week 3, Day 3
A real data engineer doesn’t say:
“Let me just load this CSV and print the head.”
They say:
“Let’s structure this folder, validate file size, and ingest in chunks with logging.”
Today’s lesson:
Python for production-grade file handling.
Files You’ll Actually Handle in the Wild
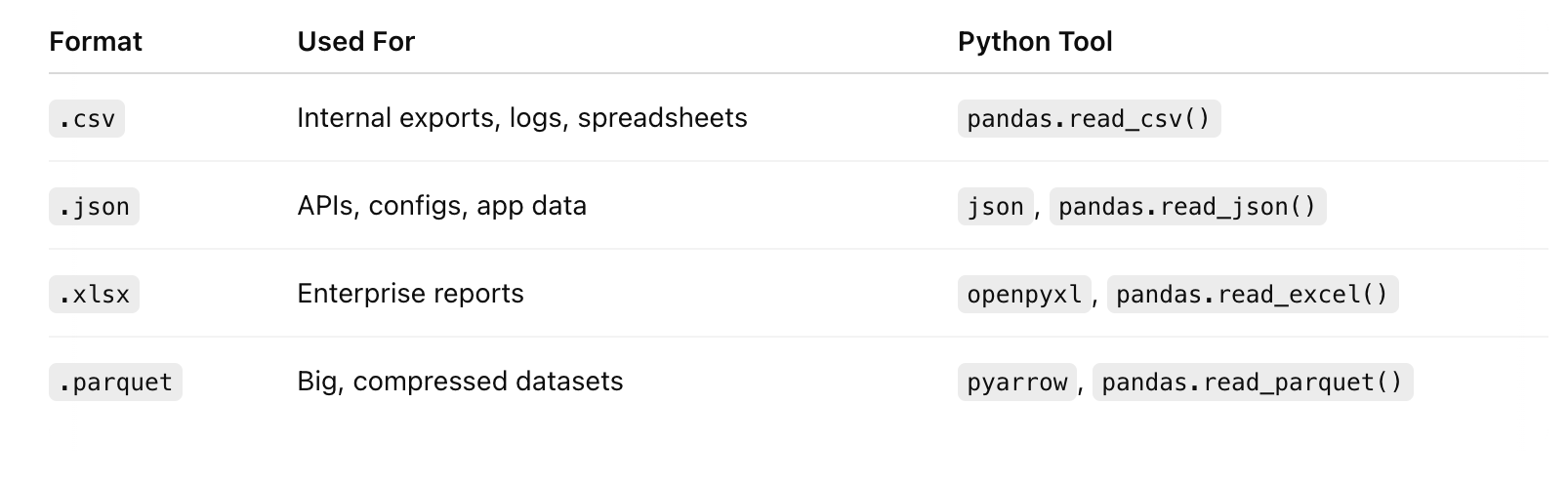
You’re not reading files for fun.
You’re turning them into clean, usable, repeatable pipeline inputs.
Real Example: Chunk Reading a Large CSV
import pandas as pd
chunks = pd.read_csv("big_sales.csv", chunksize=50000)
for i, chunk in enumerate(chunks):
cleaned = chunk.dropna(subset=["customer_id"])
cleaned.to_csv(f"cleaned_sales_part_{i}.csv", index=False)This is how DEs handle:
Large files without crashing memory
Splitting clean output into batches
Ensuring pipeline resiliency