Scale Does Not Break Your Code. It Breaks Your Assumptions.
I was wrong about retries. It cost a million users.

I remember the exact moment I realized I had no idea what I was doing.
It was my first week at Meta. I had just been handed access to one of the most complex data pipelines I had ever seen. A DAG running on 40 trillion events a day. Likes. Messages. Video views. Sensor pings from devices most people don’t even know exist.
I sat there thinking, I have built pipelines before. Real ones. For Fortune 500 clients. I know Spark. I know SQL. I know how to ship. I’ve got this.
I did not have this.
The first thing that humbled me was not the complexity of the code. It was how wrong my assumptions were.
Before Meta, I assumed deduplication was a solved problem. You write the logic once. It works. Done. At 10 million rows that is true. At 40 trillion events, I was generating duplicates that lived quietly in production for weeks before anyone noticed. And by the time we caught it, half the company was downstream of that bad data.
The code was not wrong. My assumption was wrong.
The second assumption that broke me was around retries. In most systems, if a job fails you retry it. Simple. Safe. Standard practice. At Meta scale, a retry meant potentially processing the same event twice. Which meant potentially double charging a million users. Which meant a P0 incident at 2am with half the engineering org on a call.
I had never once thought about idempotency as a design requirement. At scale it is not a nice to have. It is the difference between a working system and a crisis.
The third assumption was around SLAs. I assumed if a job had a 4 hour SLA and ran in 2 hours in staging, we were fine. Until the cluster was hot. Until three other high priority jobs were competing for the same resources. Until my 2 hour job was at hour 6 and my SLA was breached and I was explaining to my manager why downstream dashboards were empty.
Here is what I learned from all of this. The engineers who survive at that level are not the smartest ones in the room. They are the ones who documented every assumption their system made and then intentionally tried to break each one. Not in production. Not after an incident. Before it ever went live.
That is the skill nobody teaches you. Not in bootcamps. Not in certifications. Not in any course I have ever taken. You learn it by being on the wrong side of an incident and spending 6 hours in a war room tracing back to the assumption you made three months ago that seemed totally reasonable at the time.
Or you learn it here. Before it costs you a night of sleep.
The framework below is the exact checklist I run before any pipeline goes to production. The same one I wish someone handed me in my first week at Meta.
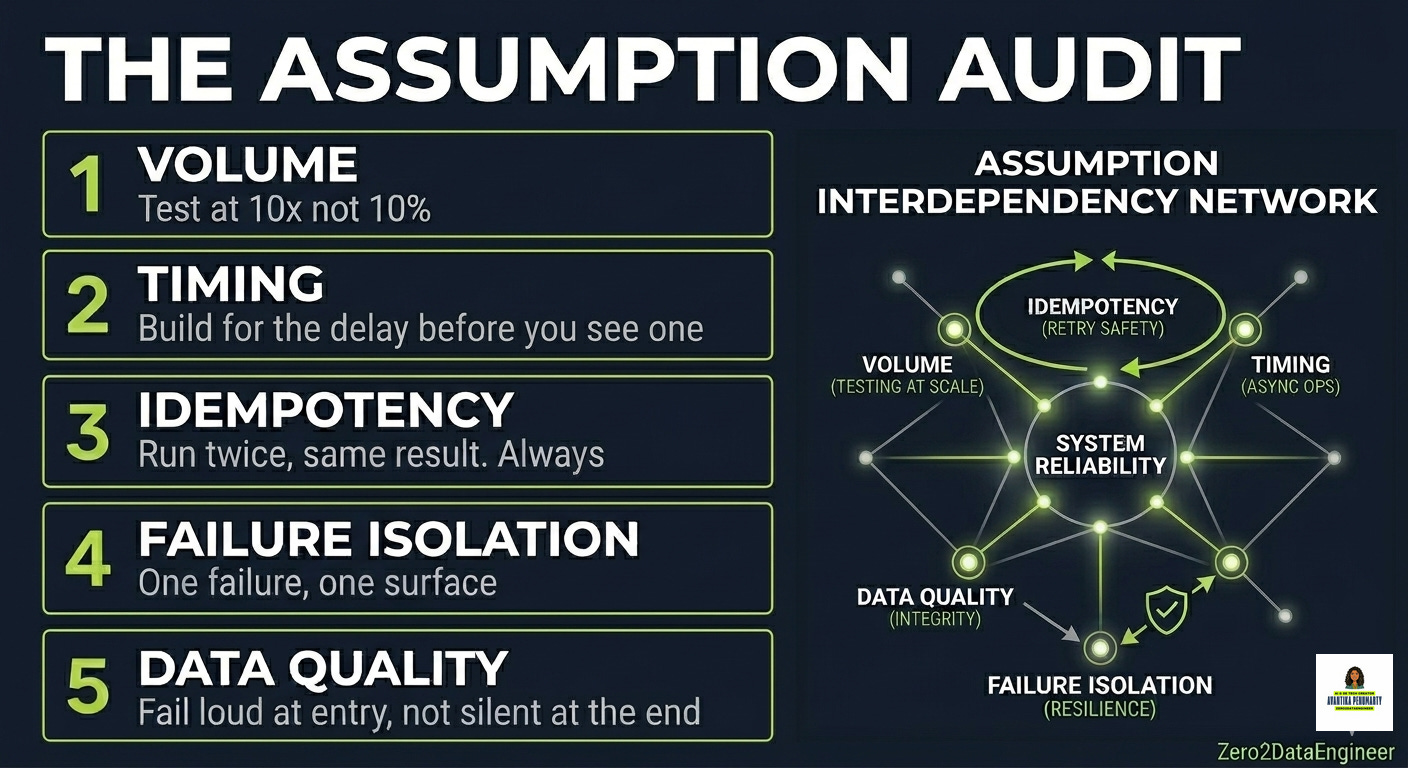
THE ASSUMPTION AUDIT: HOW TO BREAK YOUR PIPELINE BEFORE IT BREAKS YOU
After years of building at scale, I now run every pipeline through five assumption categories before it goes live. Not because I am paranoid. Because every incident I have ever been part of traced back to exactly one of these five.