

Everyone Talks About Spark. SQL Still Runs the Data World.
How modern data pipelines actually move and scale

Hi everyone,
Before we begin, I want to share a quick, honest note and sincere apologies to all my readers.
I’ve been quieter than usual over the last few months. I was dealing with some personal and health-related challenges and needed to step back briefly. Thank you for your patience, messages, and continued support it truly means more than you know.
I’m back now, and it felt right to restart with a topic that sits at the very core of data engineering one that has quietly shaped almost every system I’ve worked on.
Table of Contents
What is SQL in Data Engineering?
Why SQL is Crucial for Data Engineering
SQL for ETL vs. ELT Pipelines
Essential SQL for Data Engineers
SQL in Modern Data Engineering Tools
Best Practices for Writing SQL in Data Engineering
Future of SQL in Data Engineering
Conclusion
FAQs
Prefer listening over reading?
Are you on your way to work or heading back home?
Starting a run, folding laundry, or just taking a quiet break?
If reading feels like too much right now, I’ve got you.
I recorded an audio version of this newsletter so you can listen while you move through your day. Same ideas, same depth just in a format that fits real life.
Plug in your headphones, press play, and let SQL make sense in the background while you take care of everything else.
Introduction
Structured Query Language (SQL) remains the foundation of data engineering, enabling data professionals to design, build, and maintain scalable data pipelines. Despite the rise of modern technologies like Apache Spark and NoSQL databases, SQL’s declarative syntax and universal adoption make it indispensable in real-world data engineering workflows.
In this piece, I’ll walk you through how SQL shows up in real data engineering work, what actually matters in practice, and why it continues to be one of the most valuable skills you can invest in as a data engineer.
What is SQL in Data Engineering?
Meta story: Early in my career, I believed mastering tools would make me a great data engineer. Spark, Airflow, Kafka I chased them all. What actually made my work reliable wasn’t a tool. It was the moment I truly understood SQL as a way of thinking: describing what the data should look like, not how to move every row. That shift changed how I designed pipelines forever.
At its core, SQL (Structured Query Language) is the language we use to talk to data stored in relational systems to ask questions, shape answers, and turn raw records into something meaningful.
In data engineering, SQL is used to:
Ingest raw data
Clean and validate datasets
Transform data into analytics-ready models
Load data into warehouses and lakes
SQL acts as the linchpin of both ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) pipelines, making it the backbone of modern data platforms.
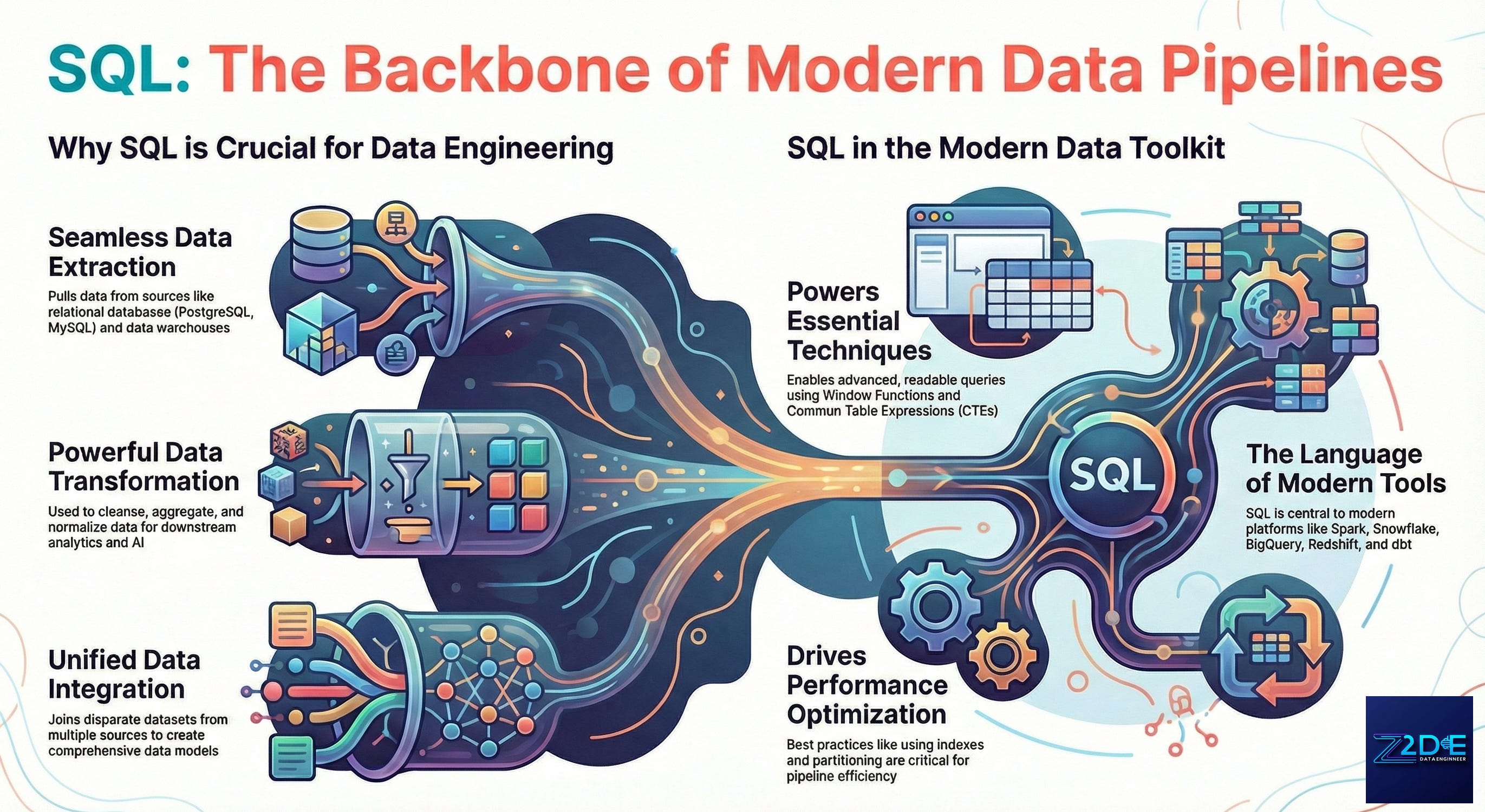
Why SQL is Crucial for Data Engineering
Project moment: On one production pipeline, we had Python transformations, custom logic, and retries everywhere and still broke SLAs weekly. The fix wasn’t a rewrite. It was replacing fragmented logic with clear, well-structured SQL. Fewer lines. Fewer bugs. More trust.
1. Data Extraction
SQL makes it surprisingly easy to pull data from structured systems like PostgreSQL, MySQL, and Oracle, and even from modern platforms that support SQL-style querying such as BigQuery and Redshift.
2. Data Transformation
Data engineers rely on SQL for cleansing, aggregation, and normalization. Features like Common Table Expressions (CTEs), window functions, and subqueries allow complex transformations to remain readable and maintainable.
3. Data Loading
In practice, SQL-powered pipelines move data into warehouses and lakes in a way that keeps analytics teams productive and downstream systems stable.
4. Data Integration
By joining datasets across multiple systems, SQL helps engineers create unified data models that power reliable reporting and decision-making.
5. Performance Optimization
Modern SQL engines such as Apache Hive, Presto, and Spark SQL provide query optimization capabilities that reduce execution time, improve resource utilization, and scale analytics workloads.

SQL for ETL vs. ELT Pipelines
Career insight: I’ve seen engineers struggle not because they chose ETL or ELT, but because they didn’t understand where SQL belongs in the system. Once you see SQL as a first-class layer not an afterthought architectural decisions become simpler.

SQL sits at the center of both approaches. In recent years, ELT has become more common simply because cloud warehouses make large-scale transformations easier and cheaper to run in parallel.
Essential SQL for Data Engineers
Interview reality: Almost every senior data engineering interview I’ve seen comes down to this section. Not syntax trivia but whether you can express business logic clearly, safely, and efficiently in SQL.
1. Window Functions
These are used when you need running totals, rankings, or comparisons across groups without losing row-level detail.
SELECT
customer_id,
order_date,
SUM(order_amount) OVER (
PARTITION BY customer_id
ORDER BY order_date
) AS cumulative_sales
FROM orders;2. Common Table Expressions (CTEs)
CTEs make complex logic easier to read, reason about, and safely modify over time.
WITH recent_orders AS (
SELECT order_id, customer_id, order_date
FROM orders
WHERE order_date > '2026-01-01'
)
SELECT * FROM recent_orders;3. Joins
Most real-world datasets only make sense once multiple tables are joined together this is where SQL earns its keep.
SELECT customers.name, orders.order_id
FROM customers
JOIN orders
ON customers.customer_id = orders.customer_id;4. Indexes and Query Optimization
Indexes improve read performance, while query planners and EXPLAIN statements help identify bottlenecks in large-scale systems.
5. Data Partitioning
Partitioning large tables improves performance in distributed systems such as Hive and BigQuery by limiting the amount of data scanned.
SQL in Modern Data Engineering Tools
Meta observation: Tools change faster than job titles. What stays constant is SQL acting as the common language across platforms the one skill that transfers cleanly when stacks evolve.
ToolPurposeSQL RoleApache HiveData warehousing on HadoopHiveQL for querying HDFSApache Spark SQLDistributed data processingSQL on DataFramesGoogle BigQueryServerless data warehouseStandard SQLAWS RedshiftCloud data warehousePostgreSQL-like SQLSnowflakeCloud data platformANSI SQLdbtData transformationSQL-based modeling
Best Practices for Writing SQL in Data Engineering
Production lesson: If someone else can’t understand your SQL six months later including you it will eventually cost time, trust, or money. Readability is not optional in production systems.
Use CTEs for complex logic
Break queries into logical steps to improve readability and maintainability.Avoid
SELECT *
Explicitly select required columns to reduce data scanning and improve performance.Leverage indexes and partitioning
Use clustering, partition keys, and indexes to optimize large datasets.Monitor query performance
Analyze execution plans using EXPLAIN statements to identify inefficiencies.Follow data governance standards
Ensure compliance with organizational policies around data security, privacy, and access control.
Future of SQL in Data Engineering
Forward-looking thought: SQL isn’t competing with new paradigms it’s absorbing them. Streaming, federated queries, and data mesh architectures are all bending toward SQL as the shared interface.
Despite the growth of NoSQL and distributed systems, SQL’s declarative nature ensures its continued relevance.
Key trends shaping the future:
SQL on streaming data using platforms like Apache Flink and ksqlDB
Federated queries enabling cross-platform data access
SQL in data mesh architectures as a shared querying layer across decentralized domains
SQL is not being replaced it is evolving alongside modern data architectures.
Conclusion
Closing reflection: Every time data systems fail, the root cause is rarely “bad data.” It’s unclear logic. SQL, when written well, makes intent explicit and that’s why it continues to matter.
SQL is far more than just a querying language. It is the backbone of data engineering, powering data ingestion, transformation, integration, and analytics at scale.
As tools and platforms evolve, SQL’s clarity, expressiveness, and adaptability ensure it remains an essential skill for data engineers, data scientists, and analytics professionals.
FAQs
Is SQL used in data engineering?
Yes. SQL is fundamental to data engineering and is used extensively for data extraction, transformation, loading, validation, and modeling.
How do I become a SQL data engineer?
Build a strong foundation in SQL and database systems, practice query optimization, learn data modeling, and gain hands-on experience with modern cloud data warehouses. Complement SQL with Python for automation and orchestration.
Is SQL still relevant in 2026?
Absolutely. SQL remains one of the most in-demand skills due to its deep integration with cloud platforms, analytics tools, and modern data stacks.
Is Python and SQL enough for data engineering?
They form a strong foundation, but data engineers also benefit from learning data orchestration tools, distributed systems, and cloud platforms.
Should data engineers know SQL?
Yes. SQL is essential for building reliable data pipelines, modeling data, and ensuring data quality.
What are some of the best SQL courses for data engineers?
PostgreSQL for Everybody (Coursera)
SQL Fundamentals (Dataquest)
The Ultimate MySQL Bootcamp (Udemy)
Complete SQL Mastery (CodeWithMosh)
Advanced SQL for Data Engineering (Udemy)
🔗 Follow Avantikka Penumarty on LinkedIn
🔒 Want to turn this into real skill?
Access interactive SQL flashcards, quizzes, and AI-powered explanations in the paid section below.
Take This From Insight to Instinct
Reading builds understanding.
Practice builds confidence.
If SQL plays a role in your job, interviews, or long-term growth, passive reading isn’t enough.
I’ve created an interactive learning extension to this newsletter designed to help you think in SQL, not just recognize syntax.
Inside the paid section, you’ll get:
🧠 Flashcards to reinforce core SQL concepts and mental models
🧪 Scenario-based quizzes that mirror real data engineering decisions
🤖 AI-powered explanations that walk you through the why, not just the answer
🏗️ Applied reasoning you can reuse in production systems and interviews
This is how you move from:
“I’ve read this”
to
“I can apply this under pressure.”
